Client side rate limiting with Go
Introduction⌗
In the systems integration space, a common scenario for an application is to acts as a middleware proxy between the client and the target server. On one side, this approach can drain out the resources on the middleware during timeouts or high network latency because of heavy computations on target or middleware server. On the other extreme, this can spam the target server during high traffic volumes. This could turn out expensive in terms of time and effort for the constant monitoring and maintenance required.
In this blog post, we will analyze the use case where the client can send many requests to the target server which can overwhelm the target server and make it unresponsive for a substantial amount of time.The examples in this blog post are available in this GitHub repository. Users are welcome to clone the repository if required and follow the commentary in the readme file to run the demo examples.
Setup⌗
We can summarize the above scenario with the figure below. This is a classic example of point-to-point integrations where the middleware acts as a proxy. In this example, every time the client calls the middleware, the middleware transforms the request, calls the target server, transforms the response that the client understands, and responds to the client. During this whole cycle, the client is blocked for each request cycle.
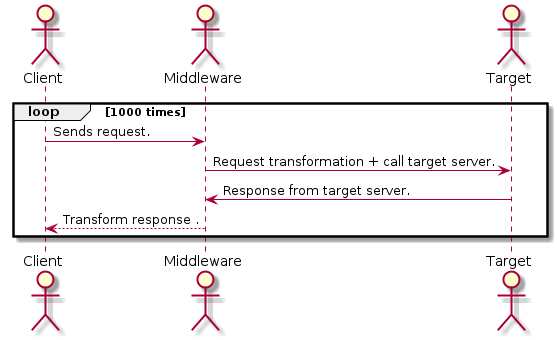
In case the target server is slow or experiences high network latency, it adds up for each iteration and can cause bottlenecks in the overall system performances.
Users can simulate this scenario by cloning the repository and run the server (middleware and target) according to the instructions in the readme.md file.
We can start the middleware and the target server by running the below commands from the application root.
prakhar@tardis (master)✗ % go run target/main.go
2020/06/18 19:58:43 starting target server
prakhar@tardis (master)✗ [1] % go run middleware/main.go
2020/06/18 20:00:54 starting standard middleware
We can then send some requests using a load testing tool called vegeta. Which will show you the response as below.
prakhar@tardis (master) % vegeta attack -duration=2s \
-rate=10 -targets=target.list --output=resp.bin \
&& vegeta report resp.bin
Requests [total, rate, throughput] 20, 10.53, 10.53
Duration [total, attack, wait] 1.9s, 1.9s, 349.681µs
Latencies [min, mean, 50, 90, 95, 99, max] 317.815µs, 404.47µs, 360.902µs,
518.276µs, 775.443µs, 943.369µs,
943.369µs
Bytes In [total, mean] 811, 40.55
Bytes Out [total, mean] 0, 0.00
Success [ratio] 100.00%
Status Codes [code:count] 200:20
Error Set:
You can increase the load on the middleware server by tweaking the parameters duration and rate and you would observe the overall decrease in the system performance. The throughput of the system would degrade drastically on increasing these values and will be even worse in case the middleware or the target server has to perform a heavy computation.
Rate limiting the middleware.⌗
By rate limiting the calls from the middleware to target server, we can avoid overwhelming the target server. We can further decouple the client from middleware by avoiding the blocking request from client --> middleware --> target server by collecting the incoming requests to the middleware in a pool. Instead of directly calling the target server, the middleware can now pull items from the pool at a constant (and controlled)rate and spreading the requests over a larger duration of time.
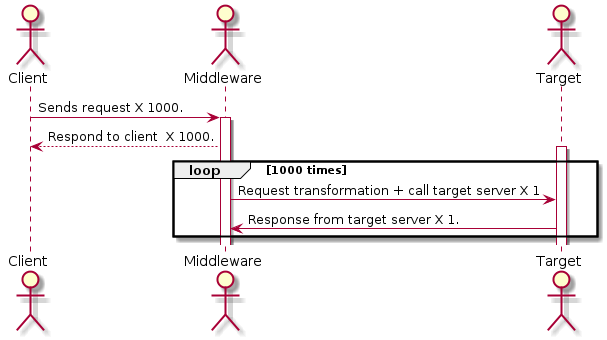
In this case, we can programatically control the rateLimit and control the rate at which the requests are sent to the target server. Users can find an implementation of this pattern here. I will highlight the most critical aspects of the implementaion below.
|
|
In the above code snippet, we can collect the incoming requests in the pool by using the submit(req *http.Request) method. the pool also provides a few utility methods start(), close() and doJob() to manage the pools life cycle. The important configurations in the setup are the rateLimit and throttle. The rateLimit will determine the period after which the throttle will unblock. This will force the pool to make limited number of call to the target server, per rateLimit period. Using this technique, we can evenly spread the bulk load over a longer duration.
The final part to this setup is the http handle function. Instead of actually calling the target server, it adds the incoming request to the pool and immediately responds to the client. This keeps the client and middleware interaction snappier and short lived.
|
|
The responsiveness of the middleware can be further improved by providing an initial buffer size to the job channel in the pool. This will immediately enqueue the first few requests almost immediately responding the client. You can actually observe the performace improvement by running the ratelimiting middleware against the target server and increasing the load on the middleware.
Tradeoffs⌗
In this approach discussed in this blog, we have improved overall the availability of system and the responsiveness of the middleware. This improvements however come with certain tradeoffs. Few significant ones are :
- The client will not be able to receive the transformed response anymore as in the original case. This response has to be communicated to the client via some other means.
- High memory and CPU consumption on the middleware because it has to store the incoming requests and manage the throttle rate.
- In this approach we do not use up all the CPU cores, because the idea is to throttle the out going requests to avoid spamming the target server.
- Needs considerable evaluation on how to handle the error scenarios and how to communicate the errors to the client.
Conclusion⌗
As I have mentioned in my earlier posts, Go provides some excellent constructs which can be utilized to create higly decoupled and distributed systems. Creating system tools like web-proxies, reverse-proxies, load balancers and rate limiters are extremely trivial using Go. In the upcoming posts, I will explore these patterns even more.
For the readers, if you find any issues with the blog post, I would request you to add them as an issue here. I will be more than happy to reply to any comments or queries.
Thanks for reading !!
References⌗
- vegeta documentation.
- example rate limiting from golang wiki.
- examples for using vegeta